HPC
Parallel and High Performance Computing Project
Project Overview
- When
- 04/2025 – 06/2025
- Duration
- 2 months
- Context
- EPFL Master
- Stack & Skills
-
C++ MPI CUDA SLURM BASH GPU Matlab
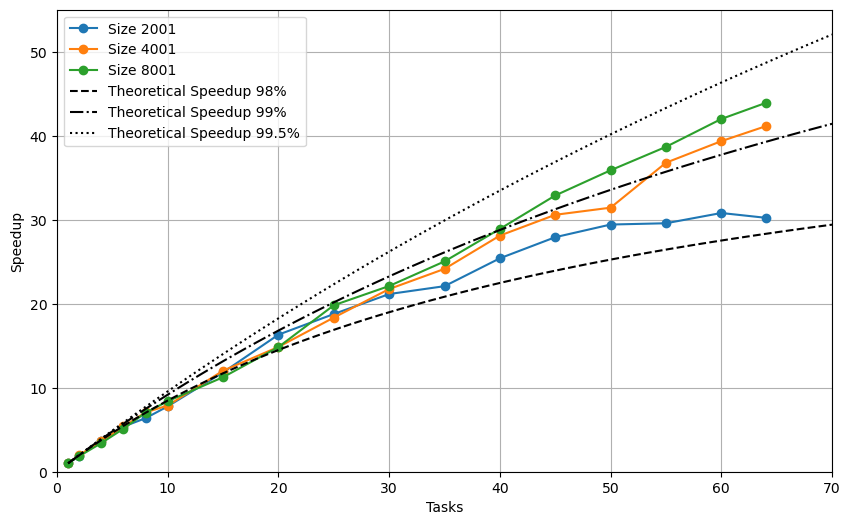
For the Parallel and High Performance Computing course, I parallelized a C++ tsunami simulation based on the shallow-water equations with both MPI and CUDA. The MPI version uses domain decomposition with ghost-row exchanges and reproduces the scaling behavior predicted by Amdahl's and Gustafson's laws. The CUDA version explores block- and grid-size tuning to balance workload distribution and hardware utilization. Both implementations deliver significant speedups, validating the efficiency of CPU- and GPU-based approaches.